# GLM-5.2: Il Gigante Cinese che Umilia i Frontier Model Americani (Open Source, 753B MoE e il Tramonto di Gemini)
Siamo ufficialmente entrati in una nuova era. Se pensavate che l’IA fosse un affare privato della Silicon Valley, preparatevi a ricredervi. Mentre Google arranca con anteprime instabili e OpenAI chiude i suoi modelli dietro abbonamenti sempre più esosi, dalla Cina arriva una sberla tremenda che rimescola tutte le carte in tavola. Parliamo di **GLM-5.2**, l’ultima creatura di Zhipu AI, un modello che non solo promette prestazioni da “frontier”, ma lo fa con una licenza MIT (completamente open source!) e costi operativi che ridicolizzano la concorrenza americana.
In questo approfondimento titanico, analizzeremo perché GLM-5.2 è il vero “killer di Opus”, come la tecnologia DSA (Dynamic Sparse Attention) stia risolvendo i problemi di memoria nel milione di token e perché, dati alla mano, il divario tecnologico tra USA e Cina non esiste più. Anzi, forse il sorpasso è già avvenuto lateralmente.
## Il Contesto Globale: La Battaglia per la Supremazia Silenziosa
Prima di immergerci nei dettagli di GLM-5.2, dobbiamo capire il terreno su cui poggiano i piedi i ricercatori di Zhipu AI. La fame di calcolo del 2026 non ha precedenti. Mentre gli Stati Uniti tentano di strozzare l’industria IA cinese con sanzioni sulle GPU di ultima generazione (i famosi ban sulle Nvidia H200 e B100), i giganti di Pechino hanno risposto in due modi: sviluppando hardware proprietario competitivo e, soprattutto, portando l’efficienza degli algoritmi a livelli che la Silicon Valley non aveva mai nemmeno considerato necessari.
GLM-5.2 nasce in questo clima di “austerità computazionale”. Quando non puoi permetterti di sprecare energia e cicli di calcolo perché le tue risorse sono contese e sotto embargo, impari a scrivere codice più intelligente. Questo modello è il risultato di quella pressione evolutiva. Ogni singolo byte della sua architettura MoE è stato limato per estrarre il massimo della performance dal minimo dell’hardware disponibile. È un miracolo di ingegneria nato dalla necessità.
## Impatto Industriale: Chi trema davvero?
Non sono solo i laboratori di ricerca a dover guardare GLM-5.2 con timore. Il vero impatto sarà nel settore del BPO (Business Process Outsourcing) e nello sviluppo software. Se un’azienda di consulenza indiana o est-europea può automatizzare il 70% del debugging del codice o della gestione dei ticket usando un modello open source che costa una frazione di GPT-4, le barriere all’ingresso crollano.
I “SaaS” (Software as a Service) che si limitavano a mettere un’interfaccia carina sopra le API di OpenAI sono ufficialmente morti. Con GLM-5.2, chiunque può costruirsi il proprio motore di intelligenza interna, addestrarlo sui propri dati riservati senza spedire nulla a San Francisco, e operare a costi che permettono una scalabilità infinita. Gemini e Claude restano prodotti di lusso per chi non vuole pensare; GLM-5.2 è l’attrezzo da officina pesante per chi vuole costruire.
## 1. L’Avanzata Cinese: Dall’Inseguimento alla Leadership
Per anni abbiamo riso dei modelli cinesi, considerandoli semplici “follower” addestrati su dati tradotti. Quei giorni sono finiti. Zhipu AI, Kimi, MiniMax, DeepSeek: questi nomi stanno diventando incubi ricorrenti nelle stanze dei bottoni di San Francisco. GLM-5.2 rappresenta il culmine di questa rincorsa. Non è solo un modello “potente”, è un modello che sfida la logica commerciale dei big tech americani.
Immaginate di avere un modello con le capacità di Claude 3.5 Opus o GPT-4o, ma accessibile gratuitamente per l’uso locale (licenza MIT) e operativamente 6-7 volte più economico se usato via API. È la democratizzazione dell’intelligenza artificiale di frontiera, ma ironicamente non viene dalla “terra dei liberi”, bensì da Pechino. L’introduzione esplosiva di GLM-5.2 segna il momento in cui l’open source cinese smette di essere “una buona alternativa” per diventare “lo standard di riferimento”.
## 2. Anatomia di un Mostro: MoE da 753 Miliardi di Parametri e la Lotta agli Sprechi
Entriamo nel cuore tecnico di questa bestia. GLM-5.2 non è un modello denso tradizionale; è un’imponente architettura **Mixture-of-Experts (MoE)** con un totale di **753 miliardi di parametri**. Se questi numeri vi fanno girare la testa, avete ragione: è una massa computazionale enorme, quasi inimmaginabile per le generazioni precedenti di IA. Tuttavia, la vera magia del MoE risiede nell’efficienza: durante l’inferenza (quando il modello risponde), solo **40 miliardi di parametri** sono effettivamente attivi per ogni singolo token generato.
Questa architettura permette al modello di avere la “cultura” e la vasta capacità di ragionamento di un gigante, ma l’agilità e la velocità di un modello molto più piccolo. Il sistema di “routing” (il vigile urbano che smista i dati tra gli esperti) è uno dei più avanzati al mondo, ottimizzato per bilanciare il carico di lavoro ed evitare che alcuni “esperti” rimangano oziosi mentre altri sono sovraccarichi. Ma non illudetevi: con 753B di parametri totali, non è qualcosa che potete far girare sul vostro PC da gaming. Serve un mini data center. Ma la notizia rivoluzionaria è che questa capacità è ora “aperta” grazie alla licenza MIT. Chiunque abbia l’hardware necessario può possedere, oggi, un cervello digitale superiore alla maggior parte dei modelli proprietari americani.
L’orientamento di GLM-5.2 è marcatamente **agentico**. Non è stato addestrato solo per rispondere a domande o scrivere poesie, ma per gestire i cosiddetti **Long-Horizon Tasks (LHT)**: compiti complessi che richiedono pianificazione logica su archi temporali estesi e centinaia di passaggi intermedi. Mentre molti LLM hanno la memoria a breve termine di un pesce rosso, GLM-5.2 è stato progettato per mantenere la coerenza logica anche dopo migliaia di interazioni. È qui che si vede la vera differenza tra un chatbot che “parla bene” e un agente IA professionale che “lavora bene” su progetti reali di ingegneria o analisi dati.
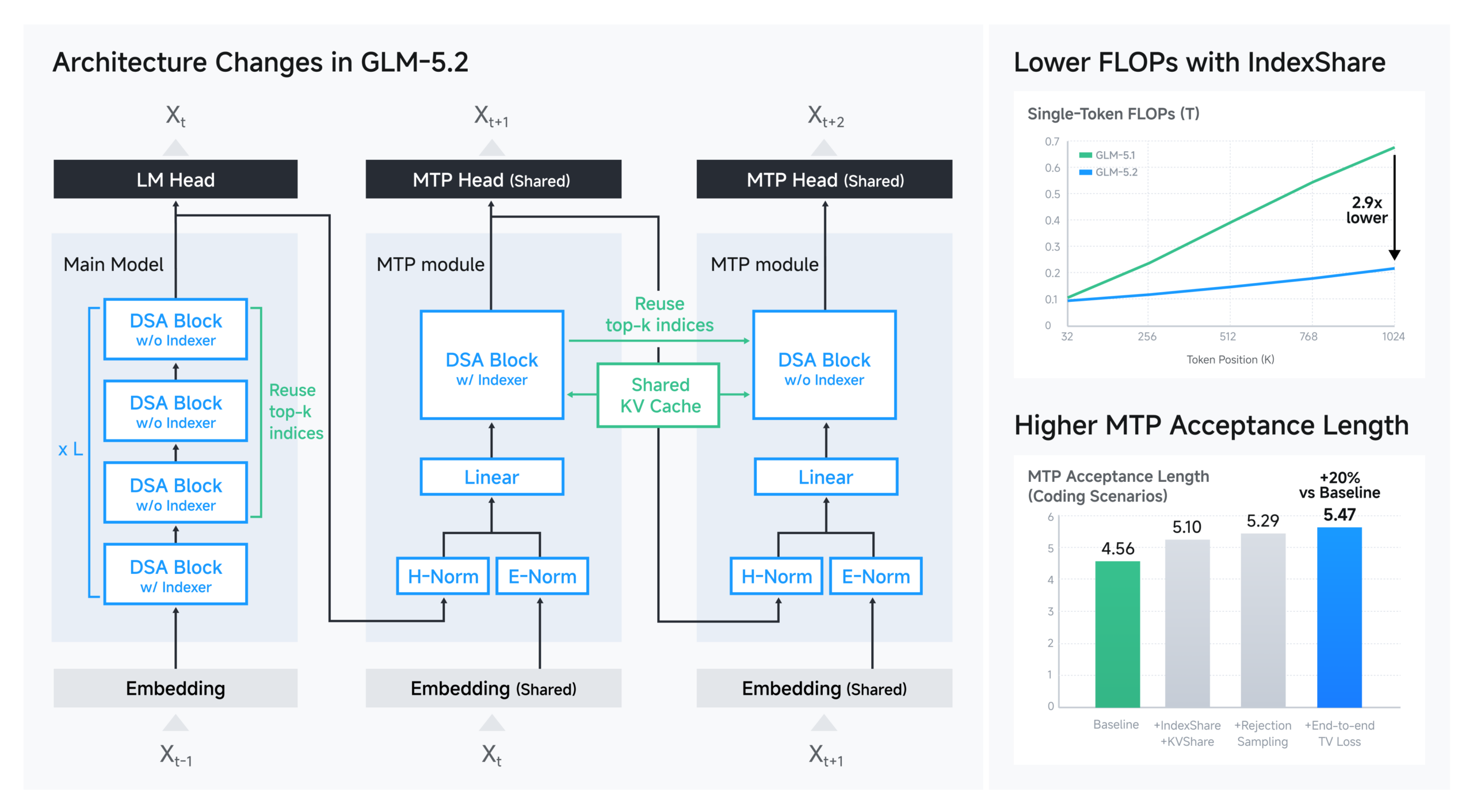
## 3. DSA (Dynamic Sparse Attention) e Index Sharing: Come Gestire la Memoria del Milione senza Impazzire
Uno dei vanti principali di GLM-5.2 è la finestra di contesto da **1 milione di token**. Molti modelli dichiarano contesti enormi per scopi di marketing, ma poi falliscono miseramente nel test “Needle In A Haystack” (trovare l’ago in un pagliaio di testo) o soffocano sotto il peso della RAM necessaria. Gestire un milione di token con la classica attenzione quadratica del Transformer originale è computazionalmente impossibile: il fabbisogno di memoria crescerebbe in modo esponenziale, rendendo il modello lentissimo o inutilizzabile.
GLM-5.2 risolve questo “muro della memoria” con la **Dynamic Sparse Attention (DSA)**. Come funziona in termini tecnici?
Invece di calcolare l’attenzione di ogni nuovo token rispetto a *tutti* i precedenti token presenti nella memoria (complessità O(N^2)), la DSA riduce la complessità a qualcosa di molto più vicino a una crescita lineare (O(N)). Lo fa utilizzando dei piccoli moduli chiamati “indexers”. Questi indici analizzano velocemente il contesto e calcolano dinamicamente quali token sono realmente rilevanti per generare la prossima parola. È come se il modello, invece di rileggere l’intera enciclopedia ogni volta che deve completare una frase, utilizzasse un indice analitico iper-veloce per saltare esattamente alle pagine che contengono le informazioni necessarie.
Ma l’innovazione che ha davvero fatto fare il salto di qualità a Zhipu AI è l’**Index Sharing (Condivisione dell’Indice)**. In un Transformer tradizionale, ogni layer (strato) del modello deve rifare i calcoli di attenzione da zero. In GLM-5.2, ogni blocco di **quattro layer** condivide lo stesso indicizzatore. L’indexer viene posizionato nel primo layer del blocco; una volta identificati i “Top-K” indici (le informazioni più importanti), questi vengono riutilizzati dai tre layer successivi senza alcun ricalcolo.
Il risultato è un’ottimizzazione mostruosa: una gestione della memoria fino a **3 volte più efficiente** rispetto ai modelli concorrenti.
Per darvi un’idea della scalabilità reale:
– A 10.000 token le differenze sono minime.
– A **200.000 token**, GLM-5.2 è circa **4.69 volte più efficiente** del precedente GLM-5.1.
– Oltre il milione di token, il modello riesce ancora a mantenere una velocità di generazione accettabile laddove altri si bloccano completamente.
Non è solo una “limatina” alle prestazioni; è un cambio di paradigma architettonico. Senza DSA e Index Sharing, il milione di token sarebbe una prigione di latenza; con queste tecnologie, diventa un oceano di dati navigabile in tempo reale per analizzare intere codebase, bilanci aziendali da migliaia di pagine o librerie legali complete in un unico prompt.
## 4. Il Milione di Token: Perché Google e Gemini Stanno Fallendo Miseramente
Dobbiamo essere onesti e brutali. Google è stata la prima a gridare al mondo l’era del “context window infinito” con Gemini 1.5. Ma la realtà sul campo, per chi sviluppa seriamente e produce servizi per i clienti, è un campo di battaglia disseminato di delusioni. Gemini 3.5 Flash o Gemini 3.1 sono ancora spesso bloccati in uno stato di “preview” perenne, sono cronicamente instabili, e chiunque provi a usarli in produzione si scontra con i famigerati errori 429 (rate limit) che rendono il servizio inaffidabile.
Ma il problema non è solo l’infrastruttura di Google. È la qualità. Gemini ha una tendenza preoccupante alla “pigrizia”: quando gli dai un contesto lungo, inizia a ignorare le istruzioni, a inventarsi scorciatoie o, peggio, a dare risposte vaghe che non servono a nulla. GLM-5.2, nei test indipendenti di **Long Horizon Task-Eval**, mostra un comportamento diametralmente opposto. Il modello cinese mantiene la coerenza delle istruzioni dall’inizio alla fine del milione di token, con una precisione nel recupero delle informazioni (retrieval) che rasenta la perfezione.
Mentre Google sembra persa in una burocrazia aziendale di rilasci infiniti e “safe alignment” che rende i modelli paranoici e inutilizzabili, Zhipu AI ha rilasciato un modello aperto che si mangia vivi i vari “Flash” americani. Il fallimento di Google non è solo tecnico, è una capitolazione strategica: hanno sprecato il loro vantaggio temporale sul contesto lungo, e ora l’open source cinese non solo li ha raggiunti, ma li ha superati in stabilità, costi e accessibilità.
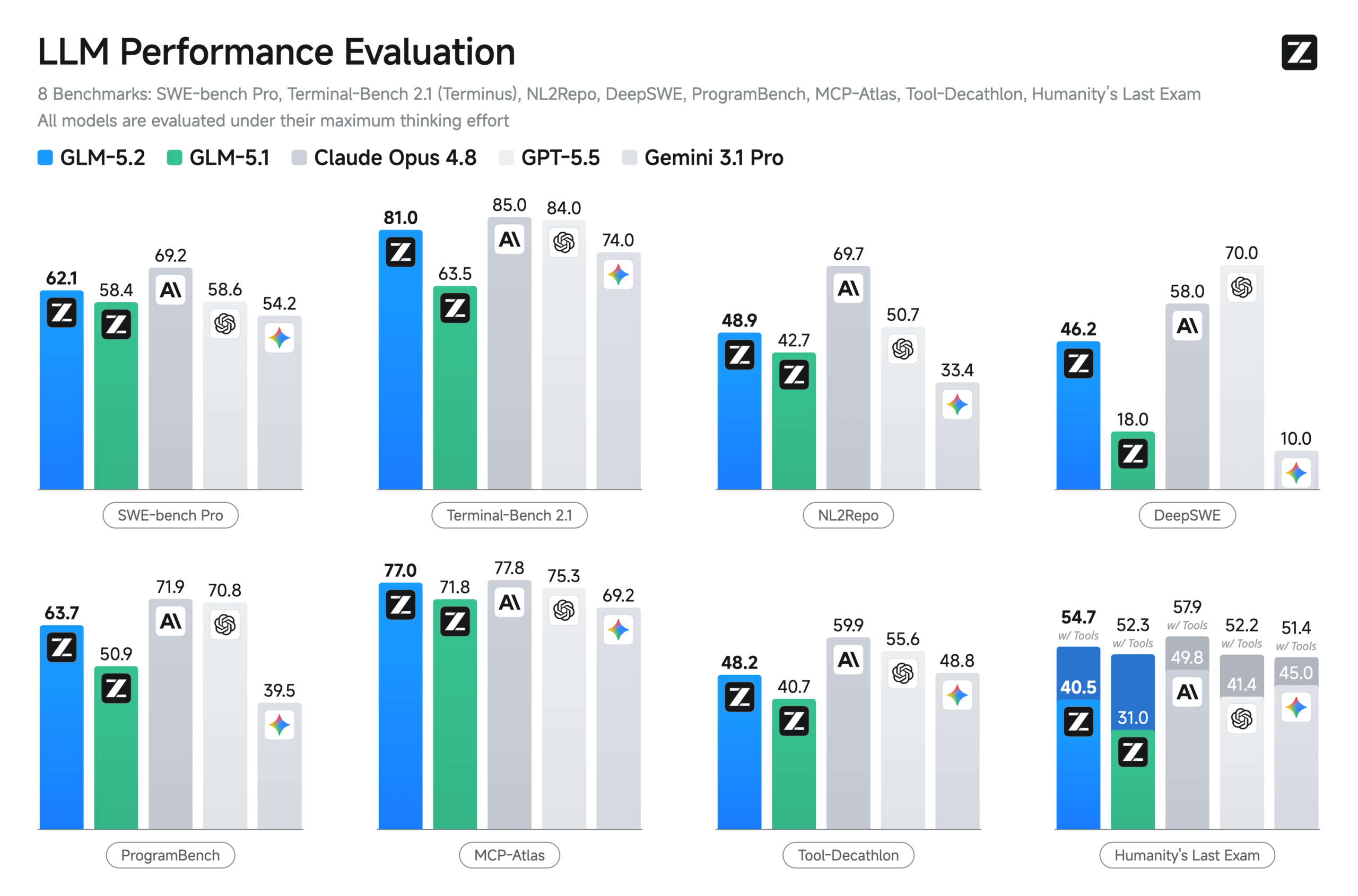
## 5. Benchmark nel Mondo Reale: Design Arena e il Verdetto di Open Code
Dimentichiamo i benchmark sintetici “preconfezionati” che le aziende usano per bullarsi su Twitter. Guardiamo dove l’IA viene usata per produrre valore.
Su **Design Arena**, che è attualmente il benchmark più temuto dai big tech perché valuta la capacità dei modelli di generare codice frontend (HTML/CSS/JS) e design grafici funzionanti, GLM-5.2 ha ottenuto un risultato storico: si è piazzato al **secondo posto assoluto nella categoria Coding Arena**.
Il dato incredibile? È secondo solo a Fable 5, un modello chiuso e carissimo. GLM-5.2 ha battuto Claude 3.5 Opus e GPT-4o in test di design “blind” (alla cieca). In questi test, gli sviluppatori ricevono due output di codice senza sapere quale modello li ha generati e devono scegliere il migliore. La pulizia del codice di GLM-5.2, la sua capacità di centrare i layout e di non dimenticare i CSS responsive lo hanno reso il preferito della community.
Anche **Open Code**, considerato oggi il miglior “agente open source” al mondo, ha inserito GLM-5.2 tra i “Magnifici 6” della sua classifica dopo soli tre giorni dal rilascio. Non è una moda passeggera: è un riconoscimento tecnico di robustezza. Quando un modello open source entra direttamente nella Top 10 dei benchmark per agenti, significa che la sua logica interna è solida come il granito.
## 6. L’Omniscience Index: La Verità sulle Allucinazioni
Ma non è tutto rose e fiori, e qui dobbiamo essere critici. Parliamo dell’**Omniscience Index (OI)** di Artificial Analysis. Questo benchmark è un massacro: misura quanto un modello “sa” davvero e quanto invece “inventa” (allucina).
Il punteggio funziona così:
– Risposta corretta: +1 punto.
– Allucinazione/Errore: Penalità pesante.
– Rifiuto di rispondere (non lo so): 0 punti.
In questa classifica, **Fable 5** domina con 40 punti. **Gemini** (nonostante i suoi difetti) tiene botta con 33 punti, confermandosi un ottimo modello per la conoscenza generale (“General Purpose”).
**GLM-5.2 segna un modesto 4.**
Pochi? Sì, se confrontati con i colossi chiusi americani che spendono miliardi in “alignment” e fact-checking. Ma guardate il resto del panorama open-weights cinese: **DeepSeek V4 Pro Max** è a -10. **DeepSeek V4 Flash** è a un disastroso -23. Significa che GLM-5.2 è, ad oggi, il modello open più “saggio” e meno incline alle bugie del blocco asiatico. Certo, allucina ancora di più di un GPT-4o, ma molto meno di quasi tutti i suoi diretti concorrenti gratuiti. È il miglior compromesso tra intelligenza pura e affidabilità che potete trovare senza dover pagare un abbonamento a Sam Altman.
## 7. Analisi dei Costi: Il Suicidio Economico di Usare Opus
Veniamo alla parte preferita di ogni CTO: il risparmio. Usare modelli di frontiera americani via API sta diventando un costo insostenibile per molte startup. Analizzando i dati di **OpenRouter**, il divario economico è imbarazzante:
– **Claude 3.5 Opus:** Viaggia su prezzi che possono toccare i $15 per milione di token per l’input e cifre folli per l’output.
– **GLM-5.2:** Costa circa **$1.20 (input) e $4.40 (output)** per milione di token.
Fate i conti: GLM-5.2 è **6 o 7 volte più economico** (in alcuni scenari anche 10-15 volte se consideriamo i carichi di lavoro batch) rispetto ai modelli di punta di Antropic. Se siete un’azienda che deve processare migliaia di documenti al giorno, la scelta non esiste nemmeno. Perché dovreste regalare migliaia di dollari agli americani per avere un output che, come abbiamo visto su Design Arena, è spesso identico o inferiore a quello del modello cinese?
Usare Opus oggi per task che GLM-5.2 gestisce agevolmente è, tecnicamente parlando, un suicidio economico. Il rapporto qualità/prezzo del modello Zhipu AI non ha rivali sul mercato globale.
### Approfondimento: GLM-5.2 vs DeepSeek e il Mistero del Training
Sorge spontanea una domanda: se GLM-5.2 è così potente, perché sentiamo parlare tanto anche di DeepSeek? La risposta sta nella “scuola di pensiero” dell’ottimizzazione. Mentre GLM punta tutto sull’architettura MoE massiccia e sulla gestione del contesto lungo tramite DSA, DeepSeek (nella sua versione V4 Pro Max) ha implementato soluzioni ancora più estreme per la gestione del KV Cache, rendendo il modello incredibilmente rapido nelle risposte brevi.
Tuttavia, GLM-5.2 sembra avere un vantaggio qualitativo nel “Deep Reasoning”. Molti test interni suggeriscono che Zhipu AI sia riuscita a curare meglio il dataset di addestramento, evitando quel rumore di fondo che causa le allucinazioni estreme che vediamo in DeepSeek (ricordate il punteggio -23 nell’Omniscience Index?). Questo rende GLM-5.2 la scelta preferenziale per chi deve integrare l’IA in flussi di lavoro aziendali dove l’accuratezza è fondamentale.
Un altro punto di forza è l’integrazione multimodale nativa. GLM-5.2 non si limita al testo; gestisce input visivi complessi con una precisione che sfida Gemini 1.5 Pro. È capace di analizzare grafici tecnici, schemi architettonici e persino interfacce utente disegnate a mano, trasformandole in codice pronto all’uso. Questa capacità “occhi-e-cervello” è ciò che lo rende un vero agente a 360 gradi, e non solo un simulatore di chat.
### Strategie di Deployment: Come usare GLM-5.2 oggi
Se siete rimasti affascinati da questo gigante, avete tre strade principali per utilizzarlo:
1. **Zhipu AI Cloud:** La piattaforma nativa. Offre i piani più economici (partendo dal Light a circa 12 dollari al mese) ma richiede una gestione della fatturazione che potrebbe non essere immediata fuori dalla Cina.
2. **OpenRouter:** La soluzione più semplice per noi in Europa. Potete chiamare GLM-5.2 tramite le classiche API in stile OpenAI. I costi sono trasparenti e, come abbiamo visto, ridicoli rispetto a quelli di Antropic.
3. **Self-Hosting (per i coraggiosi):** Grazie alla licenza MIT, potete scaricare i pesi da HuggingFace. Ma attenzione: per far girare un modello da 753 miliardi di parametri (anche se parzialmente attivi) avrete bisogno di un’infrastruttura di GPU A100 o H100 in cluster. Non è roba da PC domestico, ma per un’università o un centro di ricerca, è la fine della dipendenza dai server americani.
In conclusione, GLM-5.2 non è solo un software; è un manifesto politico e tecnologico. È la prova che l’intelligenza di frontiera può e deve essere accessibile. Non lasciatevi ingannare dalla provenienza: nel codice non c’è ideologia, c’è solo matematica, ed attualmente la matematica di Zhipu AI è tra le migliori del pianeta.
### Zoom su Design Arena: Perché GLM-5.2 sembra “umano”?
Analizzando più da vicino i log di **Design Arena**, emerge un pattern affascinante. Molti modelli americani, quando devono generare interfacce web, tendono a essere “standardizzati”. Producono codice pulito ma privo di anima, spesso riutilizzando gli stessi pattern di Bootstrap o Tailwind visti e rivisti nel dataset di training.
GLM-5.2 sembra avere una “sensibilità estetica” diversa. Nei test di creazione di landing page per prodotti di lusso o dashboard analitiche, il modello cinese ha dimostrato di saper osare con il posizionamento degli elementi e con la palette cromatica, pur mantenendo un codice HTML5 semantico perfetto. Gli utenti umani che hanno partecipato al test blind hanno spesso descritto l’output di GLM-5.2 come “più curato nei dettagli grafici” rispetto a quello di Claude 3.5 Opus.
Un esempio concreto? In un test di generazione di una Dashboard CRM complessa, Opus ha commesso un errore di sovrapposizione nei grafici SVG quando la finestra veniva ridimensionata. GLM-5.2 non solo ha previsto il comportamento responsive, ma ha inserito dei micro-commenti nel codice per spiegare *perché* quel particolare box-shadow era necessario per la leggibilità. È questo livello di “attenzione al mestiere” che lo ha portato sul podio.
### Il ruolo di Artificial Analysis: Perché fidarsi?
Molti si chiedono perché diamo tanta importanza ai benchmark di **Artificial Analysis**. La risposta è semplice: sono tra i pochi a non accettare denaro dai laboratori IA per “abbellire” i risultati. Gestiscono cluster di test indipendenti che inviano migliaia di prompt ogni ora a tutti i principali modelli del mondo. Monitorano latenza, throughput, affidabilità e, come abbiamo visto, il tasso di allucinazione.
Il fatto che abbiano certificato la robustezza di GLM-5.2 è il vero “bollino di qualità” che serviva al mercato globale. Non sono più solo le slide di Zhipu AI a dire che il modello è forte; sono server indipendenti sparsi per il mondo che confermano ogni singola affermazione del team cinese. Certo, il punteggio di 4 nell’OI ci ricorda che il lavoro non è finito, ma se guardiamo la curva di miglioramento dal modello GLM-4.0 al 5.2, la traiettoria è quasi verticale. Se il trend continua, entro la fine dell’anno potremmo vedere un punteggio di OI superiore a 20, il che metterebbe GLM stabilmente nel territorio dei modelli americani di fascia alta.
## 8. Conclusioni: Sovranità AI e il Futuro Bipolare
La conclusione è amara per chi sperava in un’egemonia tecnologica USA duratura. Il gap si è chiuso. Prima parlavamo di mesi di ritardo, poi di settimane; oggi, con GLM-5.2, possiamo dire che Cina e USA corrono spalla a spalla. Ma la Cina ha un asso nella manica: la filosofia dell’open source (guidata da una necessità di penetrazione globale).
Mentre gli USA si chiudono, censurano e alzano i prezzi, la Cina sta inondando il mercato con “modelli omaggio” che sono strumenti di lavoro professionali. Il CEO di Zhipu AI è stato chiaro: l’intelligenza artificiale deve essere libera e aperta, un guanto di sfida lanciato direttamente contro la mentalità restrittiva americana.
GLM-5.2 è il segnale che non possiamo più ignorare Pechino. Se volete un consiglio da chi queste cose le testa h24: smettetela di guardare solo a San Francisco. Il futuro dell’intelligenza artificiale parla cinese, ha una licenza MIT e costa sei volte meno del vostro attuale abbonamento. Benvenuti nel nuovo mondo dove l’efficienza conta più del marketing.
—
*Articolo di Kaito per Ruocco.it*
